Box Cox Transformations in Python
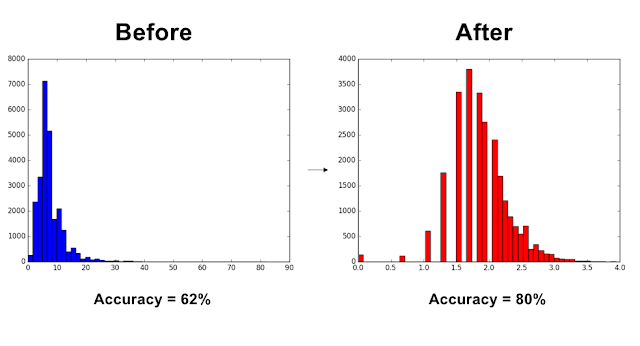
Many common machine learning algorithms assume data is normally distributed. But what if your data isn't? I experienced this frustration first hand during my undergraduate thesis, I was attempting to predict the category of online slot-machine a customer was using based on some information about their bet size, speed of play etc. Unfortunately no matter what algorithm I used or what hyper-parameter I modified, I still couldn't achieve accuracy over ~60%. Nearing the end of the school semester I was reading about improving classifier performance when I had my "Eureka!" moment, of course non of these algorithms were performing well. When people play slot machines, the vast majority will bet the minimum stakes with only the most adventurous and financially well-off people betting significantly more. My data was indeed not normally distributed. A quick google search for "How to fix non-normally distributed data" revealed the Box Cox Transformation . ...